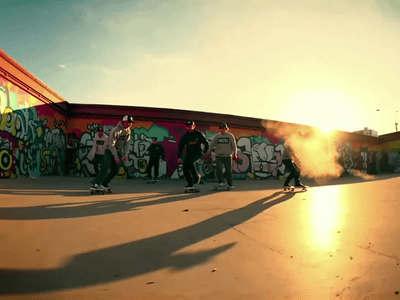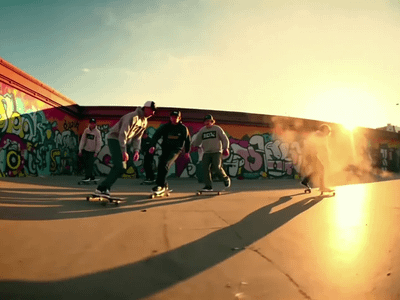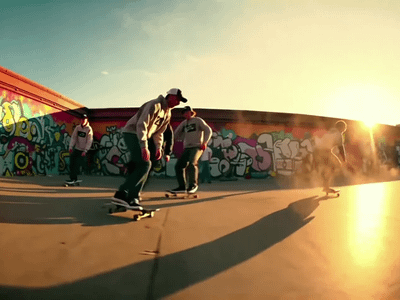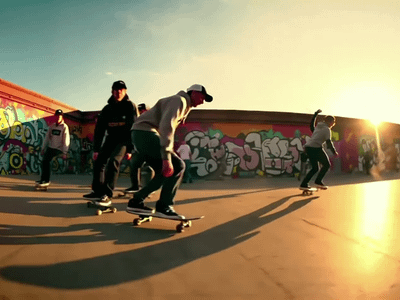Kandinsky for Text to Video
Creating excellent videos using Kandinsky
Filmmaking
Kandinsky
Text2Video
Videography
1
320




Nodes & Models
UNETLoader
kandinsky5lite_t2v_sft_5s.safetensors
VAELoader
hunyuan_video_vae_bf16.safetensors
DualCLIPLoader
qwen_2.5_vl_7b_fp8_scaled.safetensors
clip_l.safetensors
WorkflowGraphics
ModelSamplingSD3
CLIPTextEncode
Kandinsky5ImageToVideo
KSampler
VAEDecode
CreateVideo
SaveVideo
Kandinsky text‑to‑video is a diffusion‑based system that turns written prompts into short clips (around 5–12 seconds), using a keyframe‑plus‑interpolation pipeline built on top of a strong text‑to‑image backbone.
Overview
Kandinsky Video models use a two‑stage process: first generate a small set of keyframes from the prompt (often via a Kandinsky 3‑family T2I model), then interpolate additional frames between them to create smooth motion. Newer versions (Kandinsky 4 and 5) add distilled, faster variants that can produce 10–12 second 480p clips in seconds on a single GPU while maintaining good visual quality and prompt alignment.
Why it matters
Built on a mature image model, so single frames have solid composition, style control, and photorealism before motion even enters the picture.
Open or partially open implementations (code + checkpoints for earlier versions, hosted APIs for newer ones) make it attractive for experimentation and integration into custom pipelines.
Supports multiple regimes (text‑to‑video, image‑to‑video, text‑image‑to‑video), so you can drive clips purely from text or from text plus reference frames.
Typical text‑to‑video usage
You write a descriptive prompt specifying subject, action, and environment; the system generates keyframes that depict those moments, then fills in transitions for smooth motion.
Clip lengths are usually 4–12 seconds at about 480p–720p, with higher‑end variants targeting up to 10 seconds of HD‑ish quality.
Painterly or stylized motion is a common strength, especially in lighter/“Lite” models that emphasize color and smooth transitions over ultra‑sharp realism.
Use cases
Short stylized scenes or B‑roll from text descriptions, especially where an illustrative look is acceptable or desired.
Prototyping shot ideas before committing to heavier models: prompts stay the same while you refine actions, pacing, and framing.
Educational or explainer snippets that benefit from colorful, smooth motion rather than strict photorealism.
Read more